Chromium NetLog 学习与客户端结构化日志的思考
思考当前客户端日志存在的问题,并深入学习 Chromium NetLog 的设计与实现细节,从中汲取灵感,打造一套适用于我们客户端产品的结构化事件日志系统。
一、背景与现状
日志为 Troubleshooting 提供了关键信息,记录了 App 运行期间的各项上下文数据。理想的日志能够反映 App 运行时的所有状态信息,凭借这些数据,我们可以自信地定位和解决各种问题。
专业的诊断工具展示了理想日志的标准:Wireshark 能捕获并记录网络请求的每一个细节;而 Linux 与 Windows 的内存转储(Dump)文件则保存了进程运行期间的内存布局、寄存器状态等底层数据。凭借这些详尽的信息,我们可以精确还原应用程序在特定时刻的运行状态。
然而,实际情况往往并非如此。我们平时常遇到客户反馈问题时,最终提供的信息不足,迫使开发者不得不新增日志后,再要求客户复现问题以采集日志数据。
二、问题与痛点
1. 日志格式不统一
- 每个开发者都有自己的日志书写习惯——关键字、日志信息密度、时序记录等各不相同,导致日志分散且格式参差不齐。
- 在 Troubleshooting 时,查找所有关键日志项、理清时序及关联关系变得十分困难。
- 例如,分析某个请求的代理解析状态时,需要先搜索代理配置相关日志,再查看解析过程中的异常信息。若对 Proxy 解析流程不熟悉,问题排查便异常艰巨。
2. 全局状态信息丢失
- 某些问题仅靠现有日志难以还原现场。
- 例如,我们将每个网络请求封装成一个 Request 对象,并配备对应的 Handler 用于处理响应。
- 业务方提前卸载或删除 Handler 导致的野指针 Crash,仅依靠堆栈信息难以确定具体是哪一个 Handler 出现了问题。
- 因此,在 Crash 时若能 dump 当前网络模块正在处理的所有请求状态,就能大大简化问题定位。
3. 分散日志与复杂时序
- 例如,App 使用 WebSocket 实现 Push Notification 时,经常有用户反馈未能及时收到关键数据包。
- 单靠记录 WebSocket 关键时间点的日志,这些记录可能被淹没在海量日志中,难以构成完整的连接状态变迁。
- 如果能维护一个全局的 WebSocket 连接状态上下文,在关键时刻 dump 出完整信息,就能快速排查此类问题。
4. 自动化解析难度大
- 现阶段,仅依赖正则表达式对日志进行机械搜索,往往无法捕获需要跨多条日志关键字比对和关联的时序信息。
- 这使得利用大模型或 AI 进行日志自动化分析变得极其困难。
5. 日志存储方式不理想
- 当前所有模块的日志都写入一个“大而全”的日志文件中。
- 为了提取出与特定模块相关的日志,我们只能打开多个过滤结果的小窗口,手动对比时序和特征。
- 缺乏统一的关键字过滤机制,使得 Troubleshooting 工作变得繁琐低效。
三、Chromium NetLog
Chromium 的 NetLog 提供了很好的参考。NetLog 是一个专门用于记录网络堆栈行为和事件的内置日志系统,其设计思路值得借鉴。
1. 目的与范围
NetLog 记录了网络库(如 URLRequest、Socket 连接、HTTP/2 流、TLS 握手以及代理解析等)中的关键事件和状态变化,为调试和性能分析提供详尽的数据支持。
2. 数据采集与事件记录
NetLog 通过在各个网络模块内部嵌入日志点(logging points)来捕获网络活动。每个日志事件通常包含以下几个部分:
- 时间戳:标识事件发生的精确时刻
- 事件类型:例如连接建立、请求开始、响应接收、TLS 握手失败等
- 附加参数:详细描述事件的上下文,比如请求 URL、HTTP 状态码、错误码、延时统计、网络配置参数以及代理信息等
- 对象关联:许多事件都会与特定的对象 ID 关联(如一个请求或连接),使得后续分析时能重建整个请求的生命周期
这种设计允许 NetLog 支持基于时序的调试,例如将 DNS 解析、TCP 握手、TLS 握手、请求发送和响应接收等事件串联起来,呈现完整的请求轨迹。
3. 模块化与分层设计
Chromium 的网络栈设计为多个独立模块,NetLog 则以模块化的方式进行记录。每个模块(例如 Socket、HTTP、代理解析等)都负责产生日志信息,而 NetLog 系统提供统一的接口聚合、格式化和导出这些信息。这种分层设计带来的好处包括:
- 灵活性:可以对不同模块进行单独调试或关闭日志采集,降低性能开销
- 扩展性:新的网络功能模块可以方便地集成日志记录功能,而不必修改 NetLog 的核心代码
4. 数据格式与导出
NetLog 生成的日志采用结构化数据格式(通常为 JSON),便于后续通过工具进行过滤、搜索和可视化。Chrome 内置了一个 NetLog Viewer,可以将这些 JSON 日志解析成图形化的时序视图,帮助用户直观地看到请求的各个阶段和各模块之间的交互。这样的设计支持:
- 跨平台调试:JSON 格式简单而标准,方便在各种平台上进行数据交换与分析
- 自动化分析:借助结构化数据,可以利用脚本或大数据分析工具对大规模日志进行聚合、统计和性能瓶颈分析
导出的日志文件默认名称是 chrome-net-export-log.json , 这个 json 文件主要包含三个结构 constants, events, pooledData
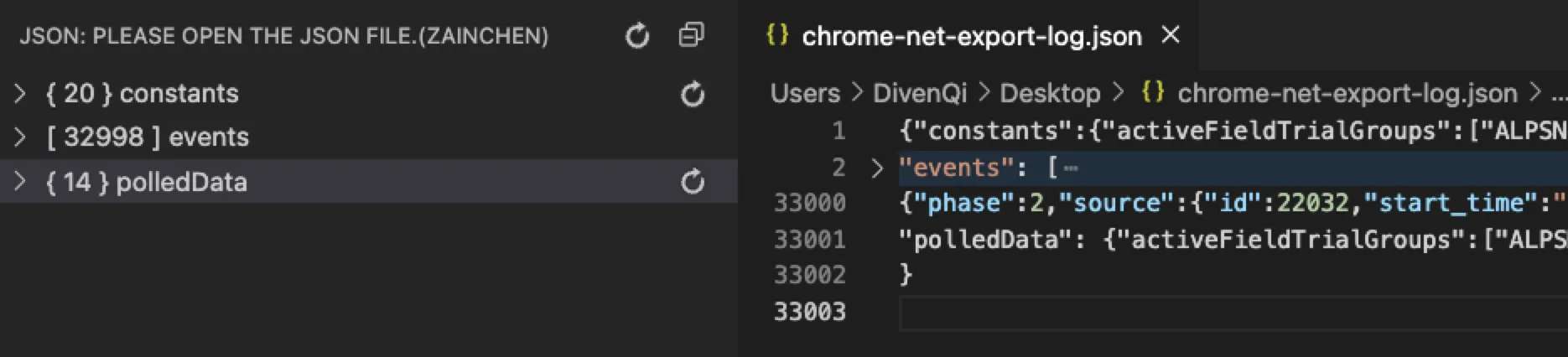
其中 constants 是常量定义,包含了 NetLog 系统中使用的各种枚举类型和错误码:
- activeFieldTrialGroups:
- 记录了当前启用的实验特性和配置组
- 例如 “ALPSNewCodepoint:EnabledLaunch”、”AdsP4:Default” 等
- 这些实验特性用于 A/B 测试和功能渐进式发布
事件类型(logEventTypes):
- 定义了所有可以记录的网络事件类型
- 包括:
- HTTP/HTTPS 相关事件
- WebSocket 事件
- DNS 解析事件
- SSL/TLS 事件
- Cache 操作事件
- Proxy 相关事件
- QUIC 协议事件
以 WebSocket 为例:
1
2
3
4
5
6{
"WEBSOCKET_HANDSHAKE_MESSAGE_SENT": 73,
"WEBSOCKET_READ_BUFFER_SIZE_CHANGED": 574,
"WEBSOCKET_RECV_FRAME_HEADER": 575,
"WEBSOCKET_SENT_FRAME_HEADER": 576
}- WebSocket 连接状态追踪
- 数据帧收发记录
- 缓冲区管理监控
- logSourceType(日志来源类型)
- 标识日志生成模块,如:
HTTP2_SESSION(10):HTTP/2会话日志QUIC_SESSION(12):QUIC协议会话日志CERT_VERIFIER_JOB(25):证书验证任务日志
- 标识日志生成模块,如:
事件阶段(logEventPhase)
NetLog 使用三种基本的事件阶段来追踪操作的生命周期:
1
2
3
4
5logEventPhase: {
"PHASE_NONE": 0,// 独立事件
"PHASE_BEGIN": 1,// 开始事件
"PHASE_END": 2// 结束事件
}- 应用场景
- 独立事件 (PHASE_NONE)
- 用于记录瞬时状态变化
- 例如:配置更新、错误发生
- 不需要配对的单一事件
- 开始事件 (PHASE_BEGIN)
- 标记一个操作或状态的开始
- 必须有对应的结束事件
- 用于跟踪持续性操作
- 结束事件 (PHASE_END)
- 对应开始事件的结束标记
- 记录操作的完成状态
- 可以包含操作结果信息
- 独立事件 (PHASE_NONE)
- 事件配对
- 生命周期追踪
- BEGIN/END 配对可以准确计算操作耗时
- 有助于发现未完成的操作
- 便于分析性能瓶颈
- 状态一致性
- 确保状态转换的完整性
- 帮助发现状态机错误
- 支持异步操作的追踪
- 生命周期追踪
- 应用场景
- 错误码(netError):
- 定义了网络栈中所有可能的错误类型,例如:
ERR_CERT_AUTHORITY_INVALID(-202):证书颁发机构无效ERR_QUIC_HANDSHAKE_FAILED(-358):QUIC握手失败ERR_SSL_VERSION_OR_CIPHER_MISMATCH(-113):SSL版本或密码套件不匹配
- 按照不同模块分类:
- 常规网络错误(如连接超时、DNS失败)
- SSL/证书错误
- HTTP错误
- Cache错误
- Proxy错误
- QUIC协议错误
- 定义了网络栈中所有可能的错误类型,例如:
5. 性能考量
日志系统在设计时需平衡详细信息采集和性能开销。NetLog 的设计提供了动态启用/禁用日志记录的机制,只有在开启详细调试时才会记录大量事件,平时保持较低的性能消耗。此外,日志采集的粒度和记录策略是可配置的,开发者可以根据实际需要选择采样率、日志级别(例如 DEBUG、INFO、ERROR)等参数,以减少对生产环境的影响。
6. 调试与 Troubleshooting
NetLog 的丰富数据帮助开发者在面对疑难网络问题时进行”时间旅行式“的调试。例如:
- 事件关联:通过关联不同事件(如请求开始与结束),可以重建出请求的完整生命周期,识别异常延时和错误点
- 细粒度诊断:记录下每个阶段的详细参数(如 DNS 解析时间、TCP 连接时间、TLS 握手详情)使得开发者能快速定位瓶颈或错误原因
7. 安全与隐私
由于 NetLog 记录了大量敏感网络交互信息,其设计中也包含了对数据的脱敏处理。某些敏感字段(如认证令牌、用户隐私信息等)会在日志中进行屏蔽或模糊化处理,以确保在调试时不会暴露过多用户数据。
四、多层次、结构化日志的思考
Zoom 客户端现有的日志大多是在开发阶段由开发者手动添加的文本日志,但日志的形式完全可以多样化。日志的主要目的是记录应用程序的运行状态,以便后续能够还原当时的场景。
日志既可以采用纯文本格式,也可以采用二进制格式,甚至可以在关键事件发生时自动触发日志记录,比如 Crash、关键业务流程失败或用户主动触发的问题反馈时。
成熟的系统通常采用多样化、多级别的日志记录策略。根据不同的触发条件,日志记录会侧重于不同类型的信息,例如:
- Android 系统在发生 ANR(应用无响应)时,会生成专门的 ANR 日志,详细记录线程状态和资源占用;
- Crash 时会产生 Tombstone 文件,保存崩溃时的完整调用栈和内存状态;
- Windows 平台发生 Crash 时,会生成 Dump 文件;
- 航空领域的”黑匣子”则代表了最极致的日志系统,在飞行全程记录关键参数,并在紧急情况下保护这些宝贵数据。
Chromium NetLog 是一个专为网络模块设计的结构化日志系统,其设计理念可以推广应用到其他场景,比如数据库操作或核心业务流程。我们可以将这种模式扩展到通用的结构化日志模块中。
1. 应用场景
数据库操作
我们的客户端采用基于 SQLite 封装的统一数据库存取模块,通过结构化日志记录对数据库操作的详细过程、耗时和异常信息,从而便于进行性能分析和问题排查。结构化日志不仅可以记录 SQL 指令、事务状态和耗时指标,还能捕获锁竞争、IO 异常和连接池状态等细节,为后续诊断提供精确依据。
核心业务流程:登录与加会
另一个例子是核心业务流程,如登录和加会。这两个流程往往涉及多个步骤,目前相关日志散落在庞大的日志文件中,甚至分布在不同的文件里。由于加会过程涉及多个模块,排查单个加会问题或分析性能时需要在多个文件间频繁切换、收集关键信息并进行时序关联,因此采用通用结构化日志方案在这些场景下显得尤为适用。
2. 需要解决的关键问题
Debug Log 的保留与淘汰
我们需要明确:原有的 Debug Log 是否还应继续保留,还是逐步淘汰?同时要设计出一个日志系统,既能满足日常开发调试需求,又能有效支持生产环境问题诊断。建议在开发阶段保留 Debug Log 以便快速定位问题,而在生产环境中则采用结构化日志记录关键业务和底层模块的信息,通过动态配置和日志级别控制,实现详略得当的日志策略。
通用且可扩展的数据类型与接口设计
设计一套通用的数据类型和接口定义非常关键。每个日志事件应包含:
- 时间戳:记录事件发生的精确时刻;
- 事件类型或步骤标识:如数据库操作类型、业务流程步骤、网络请求阶段等;
- 附加参数:包括操作细节、耗时、错误码和异常信息等;
- 关联 ID:例如 RequestId,用于关联同一操作的多个日志事件。
这些日志数据可根据不同业务或使用场景序列化为 JSON、二进制或其它格式,并分别写入相应的 payload 文件,便于后续解析和分析。
与现有日志系统的整合
考虑到目前的日志系统已相当稳定,支持异步写入、加密等基础功能,新系统必须与现有系统兼容,充分利用现有优势。具体措施包括:
- 提供兼容现有日志系统的接口,实现异步写入和加密传输;
- 渐进式集成,即在关键模块中先引入结构化日志记录,同时保留现有 Debug Log,待验证新系统稳定后再逐步推广;
- 通过配置统一管理日志级别、格式和存储路径,实现新旧日志系统的无缝衔接。
3. 日志类型及 Troubleshooting 应用场景
Log 类型
- Debug Log:以纯文本方式记录,便于阅读和快速定位问题。
- Event Log:采用结构化形式记录日志,便于解析与分析。具体包括:
- 网络相关
- WebSocket 全局连接状态:记录建立连接、重连、收发数据包统计及断开连接的各个事件和时间戳。
- 未完成请求:记录仍在请求队列中、生命期未完成的请求信息,便于排查因野指针引起的问题。
- 请求生命期:详细记录每个请求的连接状态变迁、结果、耗时等信息,涵盖各种错误码和 payload(如 DNS 解析失败、TCP 握手异常、TLS 证书验证结果、代理信息等)。
- 性能统计:记录应用存活期间发送请求的总数、各阶段连接耗时统计、DNS 解析信息等数据。
- 数据库相关
- 记录SQL指令、事务状态、耗时指标
- 捕获锁竞争、IO异常、连接池状态
- 网络相关
Troubleshooting 场景
- 手动日志分析
- 在开发阶段用于问题排查。
- 针对线上产品中用户反馈问题时附带的日志进行分析。
- 对于关键事件(如加会失败、登录失败、Crash 等)自动收集相关日志。
- 诊断与统计功能
- 在应用运行期间,定期 dump 关键状态信息(如 CPU、内存、网络请求等)。
- 针对网络请求,记录所有发出的 HTTPS 请求,包括请求是否成功、每条请求的耗时分布以及 DNS、TCP、TLS 等各阶段的耗时统计。
- 自动化日志分析
- 目前主要通过正则表达式提取关键字,但若需要跨多条日志进行比对和关联分析,则通常需要多次扫描整个日志文件。
4. 具体实例与 NetLog 借鉴
假设用户在使用 Chromium 浏览器时,遇到某个网站加载异常慢。启用 NetLog 后,系统会记录下整个网络请求的事件序列,包括 DNS 解析、TCP 连接、TLS 握手、HTTP 请求和响应等阶段。通过 NetLog Viewer,我们可以直观地看到请求各阶段的时序图,如果发现 DNS 解析阶段耗时异常长,则很可能是这一环节出现了问题,从而指导开发者针对 DNS 环节进行进一步调查和优化。
此外,通过结合时序数据与各环节之间的关联关系,我们可以进一步探索自动化根因分析的可能性。比如,通过分析历史日志数据,当检测到 DNS 解析延迟超过正常阈值时,系统可自动判断可能存在 DNS 服务器异常或网络故障问题。这种数据驱动的方法将大大提高问题诊断的效率和准确性。
回到我们的应用场景,如何关联一个请求生命周期的所有 LOG?
在 Chromium 的 NetLog 设计中,所有与同一请求相关的日志都通过 source id 进行关联。而在 zNet 中,目前涉及到三个 ID:
RequestId:在创建 zNet 请求实例时生成,具有全局唯一性,适用于关联请求的生命周期及时序信息。curl handle:可能会被多个请求复用,无法唯一标识单个请求。Web 返回的 trackingId:仅在请求成功时可获取,不适用于完整的生命周期追踪。
现有问题
当前的 troubleshooting 方式主要依赖 AfterEmitRequest 过滤所有请求,然后通过 RequestId 或 请求 URL 定位对应的请求状态日志,再结合 curl handle 追踪网络层日志(如连接状态、Request、Response 详情),最后再查找 Web 返回的 trackingId 进行进一步分析。这种方式逻辑机械、繁琐且冗余,增加了排查成本。
NetLog 方案借鉴
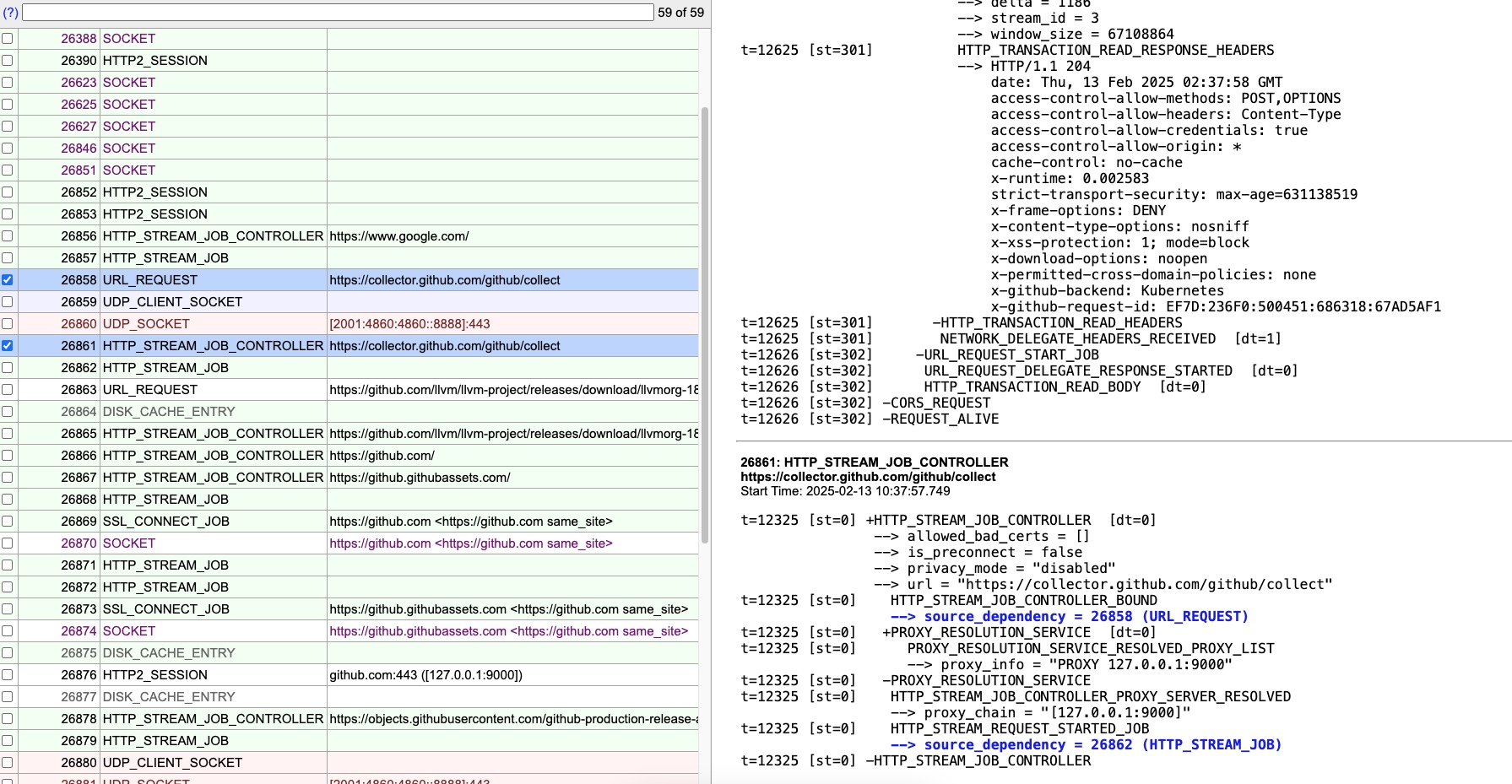
NetLog 通过 source id 关联 HTTP 请求的多个阶段(Phase),确保整个请求的所有事件都可以被统一追踪。
这里有个例子,NetLog 如何通过 source id 管理一个 HTTP 请求 Phase 的多个 events
1 | // 1. 开始 HTTP Stream Job Controller |
如果 zNet 也采用类似的方式,将 RequestId 作为主关联 ID,不仅能在请求生命周期内确保唯一性,还能减少日志筛选的复杂度,使问题分析更加直观高效。
因此,对于应用程序来说,借鉴 Chromium NetLog 的设计理念,我们可以构建一个多层次、结构化且统一格式的日志系统,有效解决现有日志中格式不统一、全局状态缺失、关键事件分散、自动化解析难度大和存储混乱等问题,从而为生产环境问题诊断、性能统计和系统优化提供坚实的数据支撑
五、通用结构化事件日志模块 : EventLogger
1. 事件类型
1 | // event_types.h |
2. 数据结构
1 | // event_logger.h |
3. 用 HTTPRequestEntity 管理 Source
在我们的网络库中,每个请求都被抽象为一个 HTTPRequestEntity,该对象全面 encapsulates(封装)请求的整个生命周期,涵盖从创建到完成的所有关键信息。
1 | class HTTPRequestEntity { |
4. 将 libCURL 日志转换为结构化事件日志
解析 CURL Debug Callback 输出,并将其转换为结构化的 Event Log,以便更好地分析和追踪请求过程。
1 | class CurlEventLogger { |
处理 CURL 请求的 Debug Callback
1 | class SBCurlRequest { |
5. 结构化的网络事件 Log 示例
1 | { |
6. 应用场景
- 代替 MEMLOG,用于线上问题 Troubleshooting
- 诊断窗口可以导入分析,产生可视化报表
自动化分析、用户 AI 训练
其实并不需要额外的训练。大语言模型本身已经具备出色的分析能力。我将上述 Log 示例作为输入,让大模型进行解析,得到的输出结果如下,可以看出其表现已经相当优秀。
Claude 的分析输出结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36第一个请求 (request_id: "1"):
1. 时间: 从 1708053600000000 开始 (约2024年2月16日10:00:00)
2. 目标: GET https://api.github.com/users/octocat
3. 请求过程:
- DNS查询: 发现 [api.github.com](https://api.github.com/) 在DNS缓存中
- TCP连接: 连接到 140.82.121.6:443 端口,连接成功
- SSL/TLS握手: 使用 TLSv1.3 和 TLS_AES_128_GCM_SHA256 加密套件
- HTTP请求: 发送带有基本headers的GET请求
- 服务器响应:
- 状态码: 200 OK
- 收到总计2280字节的响应数据
- 完整请求耗时: 875毫秒
- 整个请求成功完成
第二个请求 (request_id: "2"):
1. 时间: 从 1708053601000000 开始 (比第一个请求晚1秒)
2. 目标: GET https://nonexistent.example.com/api
3. 请求过程:
- DNS解析: 尝试解析 [nonexistent.example.com](https://nonexistent.example.com/)
- 失败: 收到 NXDOMAIN 错误(域名不存在)
- 请求终止:
- 错误代码: 6
- 错误信息: "Couldn't resolve host name"
- 整个请求失败,耗时约6秒
这个日志系统使用了不同的事件类型来追踪请求的各个阶段:
- 1000系列: DNS相关事件
- 1100系列: TCP连接事件
- 1300系列: SSL/TLS事件
- 1400系列: HTTP事件
- 1900系列: 错误事件
每个事件都包含了详细的时间戳、事件类型、阶段(开始/结束/中间)以及相关参数,这对于调试网络问题和性能分析非常有帮助。
六、总结
通过分析当前日志系统的问题并结合 Chromium NetLog 的设计经验,我们可以得出以下几点启示:
- 日志系统应该采用统一的格式和标准,便于工具化处理和自动化分析
- 需要建立完整的上下文跟踪机制,特别是在处理复杂的异步操作时
- 应该支持多级别、多类型的日志记录,以适应不同的调试场景
- 日志的存储和检索机制需要优化,支持高效的过滤和关联分析
- 要在详细程度和性能开销之间找到平衡点:既能满足日常开发调试需求,又能有效支持生产环境问题诊断的日志系统